
Big Data y Hadoop
Para entender un poco qué es Apache Hadoop1, primero debemos tener claro qué es Big Data.
Big Data
El Big Data es un término que describe el almacenamiento y procesamiento de grandes cantidades de datos, estos datos pueden ser estructurados o no estructurados.
El Big Data nació del internet, dada su habilidad de este último a generar cantidades enormes de datos en poco tiempo.

“El Big Data es como el sexo en la adolescencia: todos hablan de él, realmente nadie sabe cómo hacerlo, todos piensan que los demás lo están haciendo, entonces todos dicen que lo están haciendo.” — Dan Ariely2
Para saber diferenciar cuando se está haciendo Big Data y no solo acumulación de grandes cantidades de datos, se deben de cumplir las principales 3 Vs. Estas Vs son las siguientes:
- Volumen Contar con una gran cantidad de datos.
- Velocidad Tener la capacidad de procesar y almacenar una gran cantidad de datos rápidamente.
- Variedad Tener la capacidad de almacenar distintos tipos de datos, como lo pueden ser: archivos (Excel, CSV, Word, …), videos, textos, pdf, etc.
Actualmente existen definiciones de más Vs pero para fines prácticos nos quedaremos con las 3 esenciales.
Apache Hadoop
Historia
Fue desarrollado en Yahoo por Doug Cutting and Michael J. Cafarella. Está basado en las investigaciones realizadas en Google de MapReduce y la tecnología Bigtable.
Está principalmente desarrollado para el manejo de grandes montos de datos y para ser robusto.
Finalmente, fue donado a la fundación de Apache Software en 2006 por Yahoo, por ende, es de código abierto hasta nuestros días.
¿Qué es Hadoop?
“Apache Hadoop es un framework de código abierto que admite el almacenamiento y el procesamiento distribuido de conjuntos de datos grandes en clústeres de computadoras que usan modelos de programación simples. Hadoop está diseñado para escalar verticalmente desde una computadora hasta miles de computadoras agrupadas en clústeres, y cada máquina ofrece procesamiento y almacenamiento local." 3
Ya viendo a Hadoop como una plataforma diseñada para los datos, Apache Hadoop es una plataforma para el análisis en data lake4 que soporta herramientas de software, bibliotecas y metodologías. Tiene como principales características:
- Los componentes principales, así como la mayoría de las herramientas, con código abierto.
- Está diseñado para el manejo de grandes cantidades de datos del tipo no estructurado.
- Está escrito en Java, pero no es una plataforma exclusiva de Java
(gracias a Arceus). - Primeramente, fue diseñado para GNU/Linux, pero hay versiones para Windows disponibles.
- Es escalable verticalmente, desde un solo servidor, hasta miles de servidores.
- Corre perfectamente en sistemas con hardware empresarial o en la nube.
- Múltiples modelos de procesamiento y bibliotecas han sido incluidos a parte del tradicional procesamiento MapReduce.
- Por último, y muy importante, es tolerante a fallos.
Aquí tenemos cuestiones sumamente importantes, como lo es el hecho de que Apache Hadoop es una plataforma para el análisis de datos en data lake.
El concepto de data lake se refiere a un tipo de paradigma para el almacenamiento de datos donde estos de guardan antes de preprocesarlos, es decir, se almacenan los datos “sucios” directamente. Al contrario que otro paradigma existente, que es el data warehouse, en el cual se almacenan los datos una vez preprocesados.
Para entender de mejor manera como es que Hadoop es una plataforma del tipo data lake, vamos a ver el siguiente diagrama.
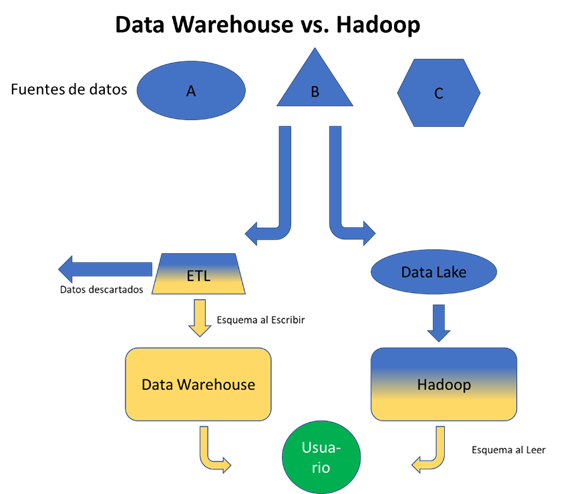
En este diagrama se pueden observar las principales diferencias en usar un data warehouse o un data lake con Hadoop. La principal es que en Hadoop no tenemos un proceso ETL (Extracción, Transformación y Lectura) anterior al almacenamiento de los datos, sino que se almacenan los datos directamente “en sucio” al data lake. Esta diferencia viene representada por colores, el azul representa que los datos no han sido preprocesados y el amarillo que ya están los datos preprocesados. En el lado del data warehouse, el preprocesamiento está en el módulo de ETL, el degradado representa este preprocesamiento de los datos. Mientras que en el data lake, este cambio está precisamente en el módulo de Hadoop.
Componentes principales de Hadoop
Ahora que ya sabemos qué es Hadoop, cómo es que se utiliza como plataforma para el análisis de datos, vamos a ver los componentes principales que tiene Hadoop.
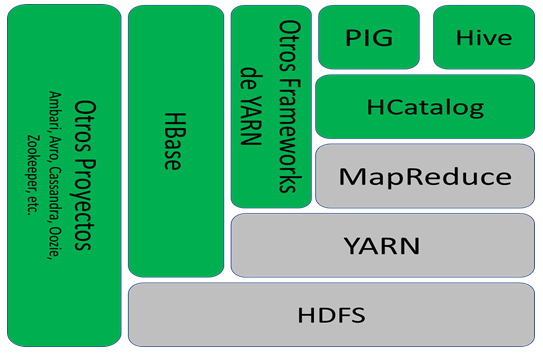
Componentes principales de Hadoop.
HDFS (Hadoop Distributed File System) es un sistema distribuido de archivos que provee acceso de alto rendimiento a las aplicaciones, está diseñado para ser tolerante a fallos en sistemas de archivos del tipo streaming. Los bloques de datos por defecto son de 64 MB, a comparación de los bloques de 4 KB que tienen los sistemas de archivos en ext4 en Linux. Los datos son replicados en múltiples servidores, por esa razón es tolerante a fallos.
YARN (Yet Another Resource Negotiator) es el planificador maestro, asignador de recursos y negociador para el clúster entero de Hadoop. Los jobs del usuario le preguntan al YARN por recursos (contenedores) y la localidad de los datos. Provee dinámicamente locación a los recursos.
MapReduce es una aplicación de YARN, provee procesamiento MapReduce del tipo tradicional.
Otros proyectos de Hadoop.
Apache Pig es un leguaje de alto nivel para la creación de programas en MapReduce dentro de Hadoop.
Apache Hive es una infraestructura construida en la parte superior de Hadoop, esta provee resúmenes, consultas (queries) y análisis de grandes cantidades de datos, todo lo anterior mediante el uso de un lenguaje parecido a SQL llamado HiveQL.
Apache HCatalog es una capa de administración de tablas y almacenamiento para Hadoop que permite a los usuarios leer y escribir datos más fácilmente, lo anterior gracias al uso de diferentes herramientas de procesamiento de datos (Pig, MapReduce).
Apache Hbase (Hadoop Database) es una base de datos columnar la cual es distribuida y escalable. Similar a Big Table de Google.
Apache Zookeeper es un servicio centralizado usado en las aplicaciones para el mantenimiento de la configuración, salud, etc. entre los nodos.
Apache Ambari es una herramienta para el provisionamiento, administración y monitoreo de los clústeres de Apache Hadoop.
Apache Oozie es un sistema de coordinación de flujos de trabajo para la administración de los jobs multiestado de Hadoop.
Apache Avro es un sistema de serialización de datos.
Apache Cassandra es una base de datos distribuida, diseñada para manejar grandes cantidades de datos a través de varios servidores.
Otros frameworks de YARN.
Debido a que MapReduce tiene diferentes limitantes, como puede ser su rendimiento o el advenimiento de nuevas tecnologías, se desarrollaron diferentes marcos en YARN para suplir estas debilidades.
Apache Tez. Muchos de los jobs de Hadoop consisten en ejecutar un complejo DAG (Directed-Acyclic-Graph) para tareas utilizando etapas independientes de MapReduce, Apache Tez generaliza este proceso y habilita esas tareas, previamente ejecutadas como estados separados de MapReduce, para ejecutarlo como un solo job que lo abarca todo.
El resultado de lo anterior es un procesamiento de jobs más rápido y el mejoramiento de un job previo orientado a batch a un query interactivo.
Tez es usado como un acelerador de MapReduce para proyectos como los son Apache Hive y Apache Pig.
Apache Giraph es un interactivo sistema de procesamiento de grafos, está construido para alta escalabilidad. Es usado por Facebook, Twitter y LinkedIn para crear grafos que representan la sociabilidad de los usuarios.
Giraph fue escrito originalmente para el uso de MapReduce de una manera no estándar para la versión 1 de Hadoop. Ahora cuenta con una implementación nativa bajo YARN que corre más eficientemente y provee al usuario con un modelo interactivo de procesamiento, el cual no está directamente disponible con MapReduce.
Es publicaciones más adelante entraremos más a detalle en cada uno de los elementos con los que cuenta Apache Hadoop.
-
Apache Hadoop o Hadoop, ambas maneras serán utilizadas. ↩︎
-
Dan Ariely es un catedrático de psicología y economía conductual nacido en Estados Unidos y criado en Israel. ↩︎
-
https://aws.amazon.com/es/big-data/datalakes-and-analytics/what-is-a-data-lake/ ↩︎